

PDFtoDB
Estrazione di dati da file PDF e salvataggio su database
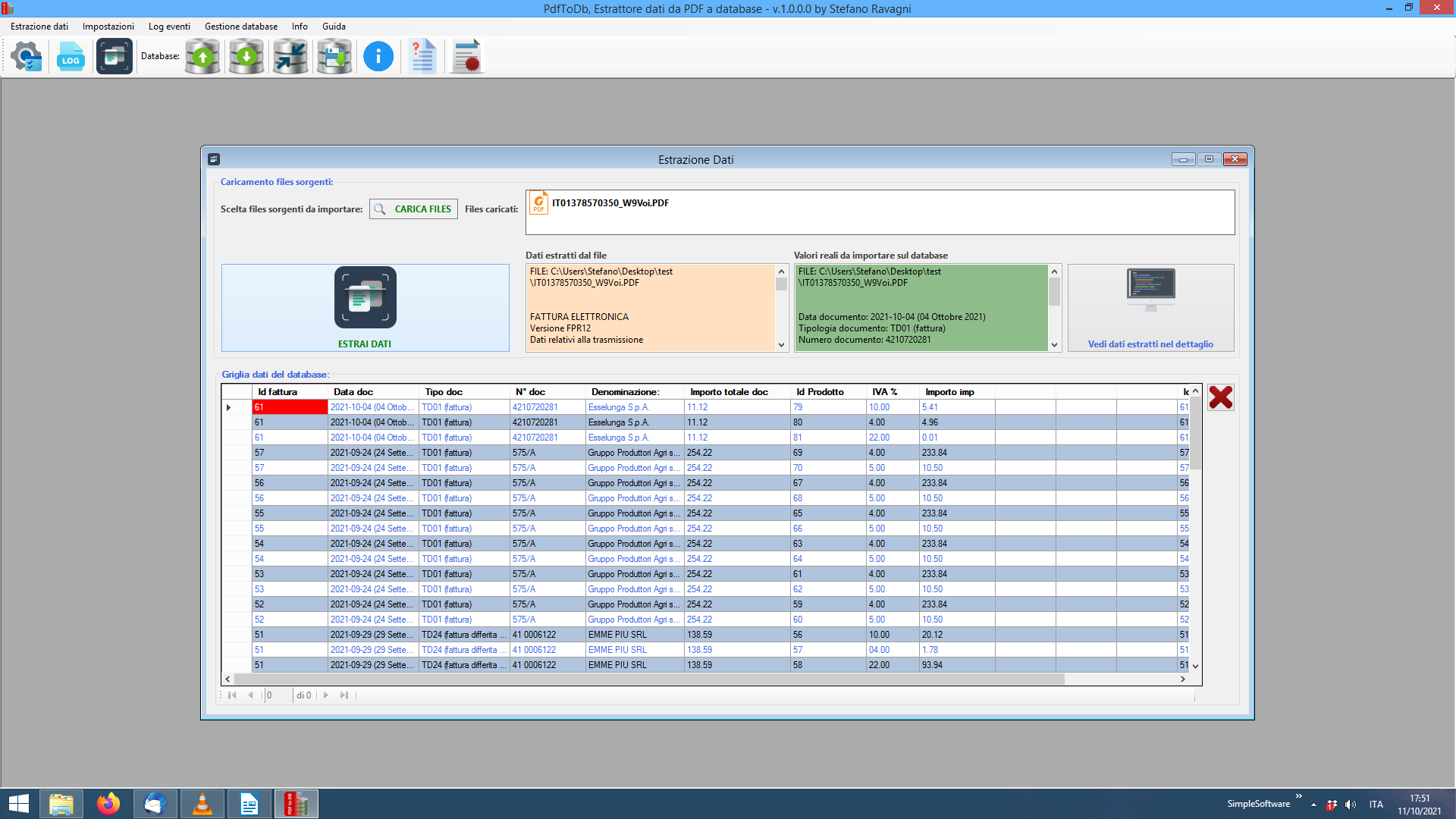
PdfToDb è un software per l’estrazione automatizzata di qualsiasi tipo di dato da files PDF e relativo salvataggio su un database (attualmente MsAccess).
I dati estratti dai files sorgente in formato PDF saranno scelti dall’utente attraverso la configurazione di 5 campi obbligatori e 5 campi opzionali derivati. PDFtoDB è in grado di leggere ogni singola parola di ogni pagina dei tuoi file PDF, individuare i campi a te necessari ed estrarli e salvarli automaticamente per te nel database… una bella comodità ! In pratica è possibile estrarre qualunque stringa da qualunque pagina del PDF di partenza!
Una volta caricati i files PDF sorgente (da 1 a “n” files) i dati saranno estratti automaticamente attraverso la semplice pressione di un bottone e verranno automaticamente salvati su un database creando così una base dati solida da utilizzare in futuro per ricerche e quanto altro si desideri.
Il funzionamento è piuttosto elementare…
Una volta configurato a dovere sarà sufficiente compiere due semplici azioni:
-
Cliccare sul tasto sfoglia e caricare da 1 a “n” files PDF sorgenti da cui estrarre i dati
-
Cliccare sul bottone estrai dati per dare il via al processo di importazione su database dei campi specificati nelle impostazioni
Non ci sono altri passaggi da compiere per usare PdfToDb !!!
Ovviamente va configurato a dovere, ragione per cui dovrai leggere la piccola guida completa per imparare ad utilizzarlo al meglio.